



- 火星双色球是使用遗传算法进行预测的。实际效果也相当不错。
- 很多朋友都希望看下神经网络应用深度学习的方式进行预测的效果。
- 我也挺好奇,这个机器学习,人工智能,号称无物不可学习的牛逼算法到底有什么神奇之处。
- 我也就是个爱好者,没有那么专业,理解不对的地方,大家见谅。废话不说,开整!
补充: 预测效果一般,但是优于随机购买
环境准备,架构设计
研发语言
机器学习,首选开发语言就是python,这是一门比较容易上手的强大的编程语言。如果说有哪一门语言最适合人工智能研发的,莫过于C,C++,这是因为深度学习需要大量的计算,是一种计算密集型的程序。而C和C++对广大应用层App研发是不友好的。需要较深的技术功底和较多的编程经验。
这就需要在底层的技术基础之上,建立起一套应用架构,让其他人可以简洁使用机器学习的相关技能。比如说计算机是一个强大的工具,但是如果没有键盘和鼠标,没有触摸屏让你操作,而是使用纸带通过打孔0和1的方式编写程序,就可以决绝99.999的电脑使用者。
python,尤其是CPython,与C语言的结合异常简单。你知道,那些科学家们,主要精力都放在算法和基础上,没有时间和经历去搞那么多高层语言。所以选择Python作为与C语言的接口,就顺理成章了。
有了这个理由,那么最开始的人工智能算法,都是用python来写的架构,那么,python库就比较权威和全面。即便其他语言再优秀,也不如python资源多,人脉广。所以,目前而言,python依旧是机器学习、人工智能的首选编程语言(绝大部分从业者深入不到使用C和C++开发的程度)。
编辑器选择
python 的编辑器很多,只要支持语法高亮、智能提示的,基本都是可以的。VSCode,甚至Sublime都是可以的。有很多在线编辑工具,Jupyter系列,可以很方便的随时随地开始程序的编写。
初学者呢,我建议跟我一样,选择pycharm,sdk包管理使用anaconda,这样相对比较简单而已。如果是从其他语言转过来做python这个可能稍有点弯需要转一下,并不难理解。适应就好了。
深度学习框架
对于pytorch和tensorflow,我比较倾向于tensorflow,不仅是出于对google的敬畏,更是看到了tensorflow的包容和胸怀。从最开始的Caffe,Theano,到后来的Keras,tensorflow和pytorch,其实本质上都差不多。只不过走到最后,只剩下了torch和tensorflow而已。
优缺点的话,pytorch更灵活,需要的资源比较多,在学术界可能使用的人会更多。他们倾向于实现各种各样奇怪的想法。但是在实际的生产企业中,tensorflow可能会更容易部署、使用。节省成本是企业使用tensor的最大动力。tensorflow的教程和文章资源也比较多,当然,很多人说tensor的api比较混乱,官方都不知道怎么想的,轮子造了一遍又一遍。不过对于初学者来说,那都是后来的事情了。
如果没有更进一步、更深入的技术突破,这两个框架应该是不相上下的,各有优劣,属于黄瓜青菜各有所爱。
配置管理
之所以把配置管理单独拿出来作为一个技术点来说,是因为配置是经常需要改动的部分,甚至说代码的调整都不如配置修改的频繁。所以,我们需要一个比较优秀的配置管理工具。这里我选择使用facebook的hydra,非常汗颜,大部分优秀的框架和IT基础建设,都是国外某某公司的,尤其是越靠近前沿科技,越是明显,国内连一个竞争对手都没有。
我堂堂大国,基建狂魔,在IT基建领域就这么落后吗?哎,不扯淡,干活儿先。
hydra为什么可以入选火星人的机器学习平台,是因为它可以在任何方法和类中自由使用。只要使用@hydra.main(config_path="",config_name="") 这个Annotation放在任何方法上,在其中就可以完整获取到整个app的配置情况。并且可以通过命令行的输入参数对其进行增加、修改。python test.py +abc=3,这样在hydra的配置中,就多了abc这个项目,使用++就可以覆盖掉当前hydra从配置文件中读取到的配置。并且,hydra是通过yaml进行配置管理的。读取可以分成文件夹、子文件夹嵌套等形式。
基础运算库
- numpy,这个不用说,矩阵运算不使用numpy,简直就是不会了。经过长时间程序员的折磨和蹂躏,numpy现在异常强大,你所要用到的大部分功能,都可以现在numpy里边查找一番。有轮子,就不要自己再去造了。
- pandas,基于numpy的数据分析工具,通常数据清洗、数据整理,使用它就对了。
- request,网络请求包,数据分析难免用到一些互联网上的资源和数据,tensorflowhub中有一部分,如果想要自定义,就通过request自己去查找,整理,配合pandas进行数据分析吧。这是基础数据整理必经之路。
- matplotlib, 绘制各种图形的工具包,matlab知道吧,这两个没啥关系。但是你只要知道,数据分析如果没有图表,就相当于人不会说话啊。用图形图像能够说明的问题,绝对不要用语言去描述。累死!
机器学习所需数据获取
我们要搞双色球,就要搞到双色球的数据,并且把这个数据做加工处理。
首先我们定位双色球开奖数据可以作为我们进行数据分析的基础数据,整理格式的话,就以期号+开奖号码作为一行来进行保存。这样读取起来,也比较方便。这个数据量并不大,大概有2700多期了。
上代码:
# 查询网路数据,并存放到指定的文件夹下。 @hydra.main(config_path="../config", config_name="config") def query_data(cfg: omegaconf.DictConfig): _logger.info('开始尝试从互联网获取最新的{}开奖数据...'.format(cfg['dataset']["data_name"])) try: resp = requests.get(SSQ_DATA_URL) if resp.status_code == 200: # 解析数据,查看数据集中最新的数据期数 lines = resp.content.decode('utf-8').replace('\n', '') # json数据格式,解析一下 ssqData = json.loads(lines) # 没有找到数据,或者系统出错 if ssqData is None or ssqData["code"] != 0: raise Exception('获取开奖数据失败!') # 获取开奖数据 lstDraw = ssqData['object'] _logger.info('获取到开奖数据的数量是:{}'.format(len(lstDraw))) # 按照期号进行排序:由小到大 lstDraw = sorted(lstDraw, key=lambda draw: int(draw['issue'])) max_issue = lstDraw[-1]['issue'] _logger.info('获取数据成功,开始更新数据文件...') # 将开奖数据按顺序写入到文件中,文件名可以是绝对路径,也可以是相对于根目录的路径。 file_name = cfg['dataset']['data_file_name'] if (file_name + '').startswith("./"): data_file = os.path.abspath(os.path.join(common_utils.get_project_root(cfg), file_name)) else: data_file = os.path.abspath(file_name) # 检查数据文件是否存在,如果不存在,创建文件夹。 if not os.path.exists(os.path.dirname(data_file)): os.makedirs(os.path.dirname(data_file)) # 仅仅写入开奖号码即可。注意将蓝球和红球号码的区分符号改为逗号 with open(data_file, 'w+') as f: f.writelines([line['issue'] + ':' + line['lotteryNumber'].replace("#", ",") + '\n' for line in lstDraw]) _logger.info('完成!当前总期数为{}期,请确认期数是否正确!'.format(len(lstDraw))) _logger.info(' 当前数据列表最大期号:{}'.format(max_issue)) else: raise Exception('获取数据失败!') except Exception as e: _logger.error(e)最终得到的数据格式:(部分,全整出来太多了。需要这个数据的,可以找我单独要。最后一位是蓝球)
2021101:02,04,12,22,29,31,01 2021102:05,09,15,24,27,30,09 2021103:10,13,15,25,29,30,15 2021104:01,07,17,20,22,28,15 2021105:10,14,15,22,27,32,09 2021106:01,04,07,14,30,31,03 2021107:02,03,17,19,25,30,01 2021108:11,15,18,24,26,32,09 2021109:02,03,10,17,20,26,16 2021110:10,13,15,24,31,32,02 2021111:17,20,22,23,26,28,06 2021112:05,06,21,25,28,33,07 2021113:04,07,10,22,27,30,02 2021114:04,06,08,14,24,27,02 2021115:02,10,12,15,24,27,08 2021116:06,14,17,18,31,33,06 2021117:03,05,17,21,27,33,04 2021118:02,06,14,18,20,31,13 2021119:03,09,10,11,28,29,13 2021120:01,07,08,12,13,18,05模型选择和创建
首先我们要清楚,我们需要训练一个什么样的模型,以及怎样训练这个模型。数据模式以及未来的预测方法,都会受到模型的影响。哦哦,应该是应该影响到模型的选择。
cnn,卷积神经网络模型。这是一个局部-全局的算法,把全局的东西分割成很多个小的局部,通过对每个小的局部进行特征提取,从而得到全局的特征分析。所以,他是一个比较适合用来做图像分析的模型。比如识别一张狗狗的图像,首先可以把图像分割成小块,这个块全蓝色,可能是天空,这一块白色三角形,可能是狗狗的耳朵等等。整体结合起来,对狗狗的图像有了认知。
rnn,循环神经网络。cnn就是在做切割-结合,切割-结合,这是无法体现时间序列的,谁早一点晚一点,他并不知道,也并不关心。而循环神经网络,则需要知道前500年,后500年,分析和学习其中的因果、相关关系。
lstm,为了解决rnn中时间维度上梯度消失的问题,引入了长短期记忆单元,这样,循环神经网络就不会无休止、绵延不绝的进行下去了,可以方便的观察出来,什么时候效果最好,什么时候已经开始没有进展。这时候,我们停止就行了。
了解了以上基础信息,我们就可以轻易得出结论,我们应该使用lstm作为我们双色球预测的神经网络模型。在时间序列中,我们可以通过对历史数据的分析,获取未来短时内的预测,也可以通过分析数据之间的联系,使用部分数据作为循环体,轻易验证我们所做的预测是否有效果。
另外,既然是预测,我们首先要了解,这个预测的原理是什么。
我理解的神经网络原理
神经网络的原型,是人的大脑神经元。作为记忆和分析问题的基础器官,它有着数十亿的数量。
我理解的神经网络,就是使用大量的数据和计算方法,作为一个个的节点(神经元),再通过这些节点之间的连接关系,去分析得到最终结果的方法。是不是不太好理解。
就是说,有一个神经元,叫做 加一神经元。 它所干的事情比较简单,从他这里过一下,就要被加一个1,3进去,4出来。5进去,6出来。理解吧。可能还有一个神经元,叫做log38787,这个数字是我瞎写的,就是以38787为底的对数值。这是一个固定的计算规则。这个神经元,就是我们神经网络中的基础构造体。每一层中,这样的神经元就有固定的个数(具体看你的配置),而数据,也是作为一个基础元素提供的,他可以认为是输入。简单来说,就是找规律。
比如以下:
输入 输出 1 1 1 2 2 3 3 5 5 8 8 13 13 21 21 34 34 ? 这是一组输入和输出,神经网络会把输入放到各个层(Dense)中,每个层里边的神经元很多,相邻两层可以做输入和输出关系。所谓一个Dense就是一组神经元的全连接。就是排列组合中的全排列。让他们任意的排列组合都可以获取到。这样通过很多个层次的输入输出,很多神经元的输入和输出,可以找到很多个从输入到输出的路径。
比如1--> 1,有很多个路径,路径就是神经元的连接。比如【乘一】神经元,一个神经元就是一个路径。比如 经过一个 【加一】神经元,再经过一个【减一】神经元,也可以得到输出 1。这就是两个路径。
一个全连接的神经网络中,可能会有千百亿个神经网络,对于每一个输入和输出,都可以查找到数以亿计的路径。对于人工智能的训练来说,就是在这些路径中,查找同时可以满足所有输入可以达到输出的路径。
通过以上的表格,人类可以轻松的得到结论:这是一个斐波那契数列。但是如果是仅仅以上几条输入-->输出的对应关系,交给神经网络去训练,可能得不到正确的结果,就是因为神经网络中,是否可以得到那个斐波那契神经元,是一个未知数。很可能还有千百个路径,都可以得到同样的结果。当然,如果神经网络中有一个是斐波那契神经元,可能一下就选中它了,最简单最直接,最符合条件。
实际的使用中,往往不是这么简单的函数关系,很可能是最终找到了一条神经元路径,上面可能有几万个计算节点。但是这个路径可以满足目前所有数据的输入--->输出的现象。这就是训练的过程。如果训练量不够,或者说数据量不够,很可能拿不到正确的路径,也就是模型。下一个没有经过训练的数据安进来,结果就是对不上。如果数据量足够多,那么这路径对于类似的数据来说,也就越加完美。
说了好多废话。来看我的模型是怎样搭建起来的。
# 名称 name: lstm_dense # 随机失活概率 dropout_rate: 0.3 # 长短期记忆单元数量 lstm_units: 64 # 步进 strides: 3# 使用tensorflow创建keras模型---创建神经网络。 def build_model(loop_unit=256, front_size=6, front_vocab=33, lstm_units=64, dropout_rate=0.3, back_size=1, back_vocab=16, strides=3, **kwargs): # 这是一个多输入模型,inputs用来保存所有的输入层 inputs = [] # 这是一个多输出模型,outputs用来保存所有的输出层 outputs = [] # 前区的中间层列表,用于拼接 front_temps = [] # 后区的中间层 back_temps = [] def build_x(p_x_input, vocab): # 双向循环神经网络 v = layers.Bidirectional(layers.LSTM(lstm_units, return_sequences=True))(p_x_input) # 随机失活 v = layers.Dropout(rate=dropout_rate)(v) v = layers.Bidirectional(layers.LSTM(lstm_units, return_sequences=True))(v) v = layers.Dropout(rate=dropout_rate)(v) v = layers.TimeDistributed(layers.Dense(vocab * strides))(v) # 展开所有层 v = layers.Flatten()(v) # 做层的全连接 v = layers.Dense(vocab * strides, activation='relu')(v) # 保存输入层 inputs.append(p_x_input) return v # 处理前区的输入变换 for i in range(front_size): # 输入层 x_input = layers.Input((loop_unit, front_vocab), name='x{}'.format(i + 1)) x = build_x(x_input, front_vocab) # 保存前区中间层 front_temps.append(x) # 处理后区的输入和变换 for i in range(back_size): # 输入层 x_input = layers.Input((loop_unit, back_vocab), name='x{}'.format(i + 1 + front_size)) x = build_x(x_input, back_vocab) # 保存后区中间层 back_temps.append(x) # 连接 front_concat_layer = layers.concatenate(front_temps) back_concat_layer = layers.concatenate(back_temps) # 使用softmax计算分布概率 for i in range(front_size): x = layers.Dense(front_vocab, activation='softmax', name='y{}'.format(i + 1))(front_concat_layer) outputs.append(x) for i in range(back_size): x = layers.Dense(back_vocab, activation='softmax', name='y{}'.format(i + 1 + front_size))( back_concat_layer) outputs.append(x) # 创建模型 model = models.Model(inputs, outputs) # 创建优化器 optimizer = get_optimizer_from_config(kwargs) # 指定优化器和损失函数 model.compile(optimizer=optimizer, loss=[keras.losses.categorical_crossentropy for __ in range(front_size + back_size)], loss_weights=[2, 2, 2, 2, 2, 2, 1], metrics=['accuracy']) # 查看网络结构 # model.summary() return model训练模型以及算法设计
好,模型创建好了,就要对其进行训练。训练相对就比较简单了。
就是造好数据,送给模型去计算,去找到那条符合所有输入-->输出的路径。
# 选取不同的评价函数,规定精准度,自定义号码分类器 def train_ball_classifier(model, train_data, val_data, train_args): _logger.info('Starting training with {} GPU(s) detected.'.format(len(tf.config.list_physical_devices('GPU')))) use_multiprocessing = False num_workers = 1 if train_args.get('multiprocessing', False): use_multiprocessing = True num_workers = train_args.get('multiprocessing') model.fit(train_data, val_data, validation_freq=train_args.get('validation_freq', 1), batch_size=train_args['batch_size'], epochs=train_args['epochs'], use_multiprocessing=use_multiprocessing, workers=num_workers, ) return model使用模型进行号码预测
拿到了模型之后,这里指的模型是训练好的模型。
我就可以使用这个模型进行预测活动了。开心不。
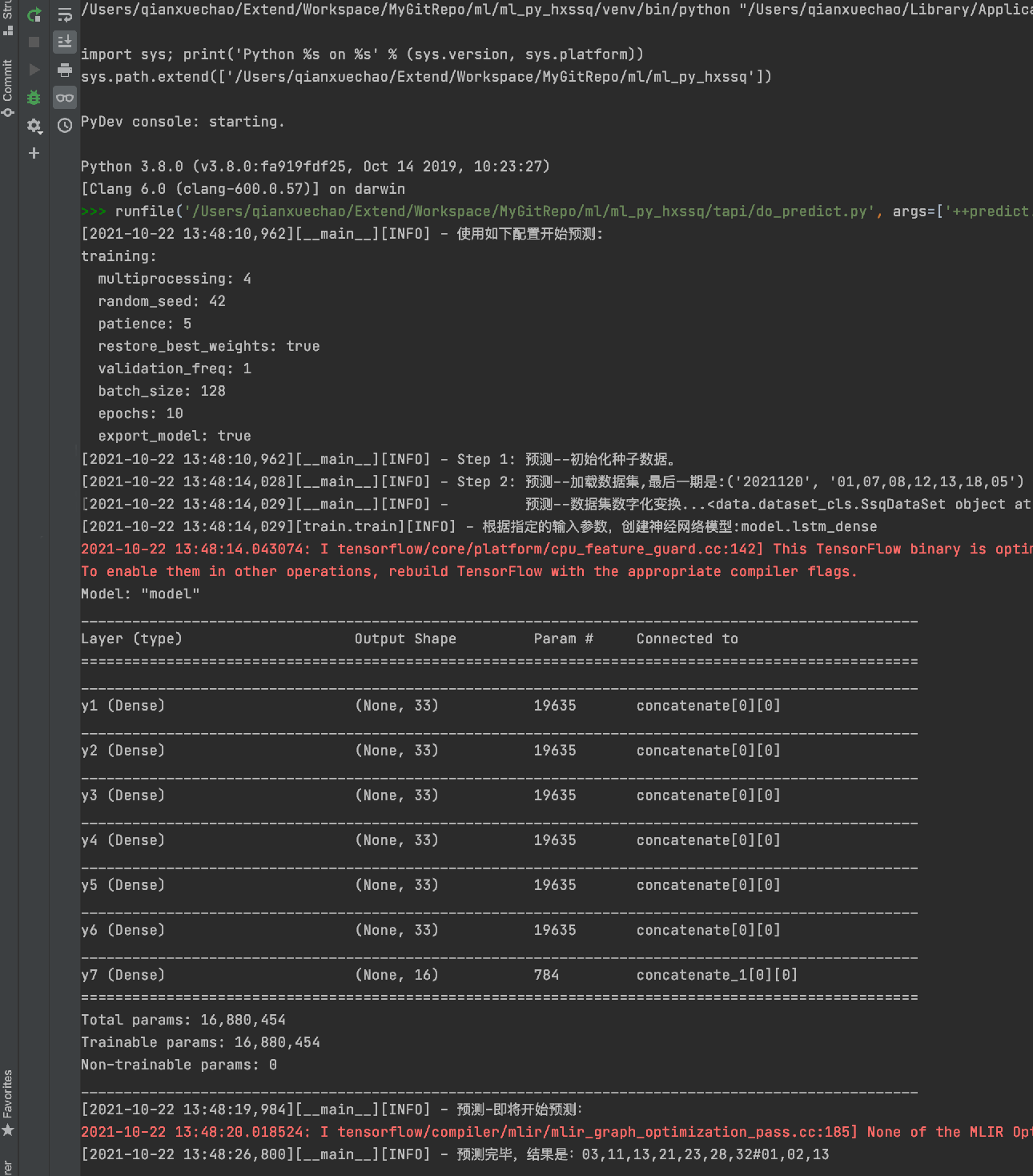
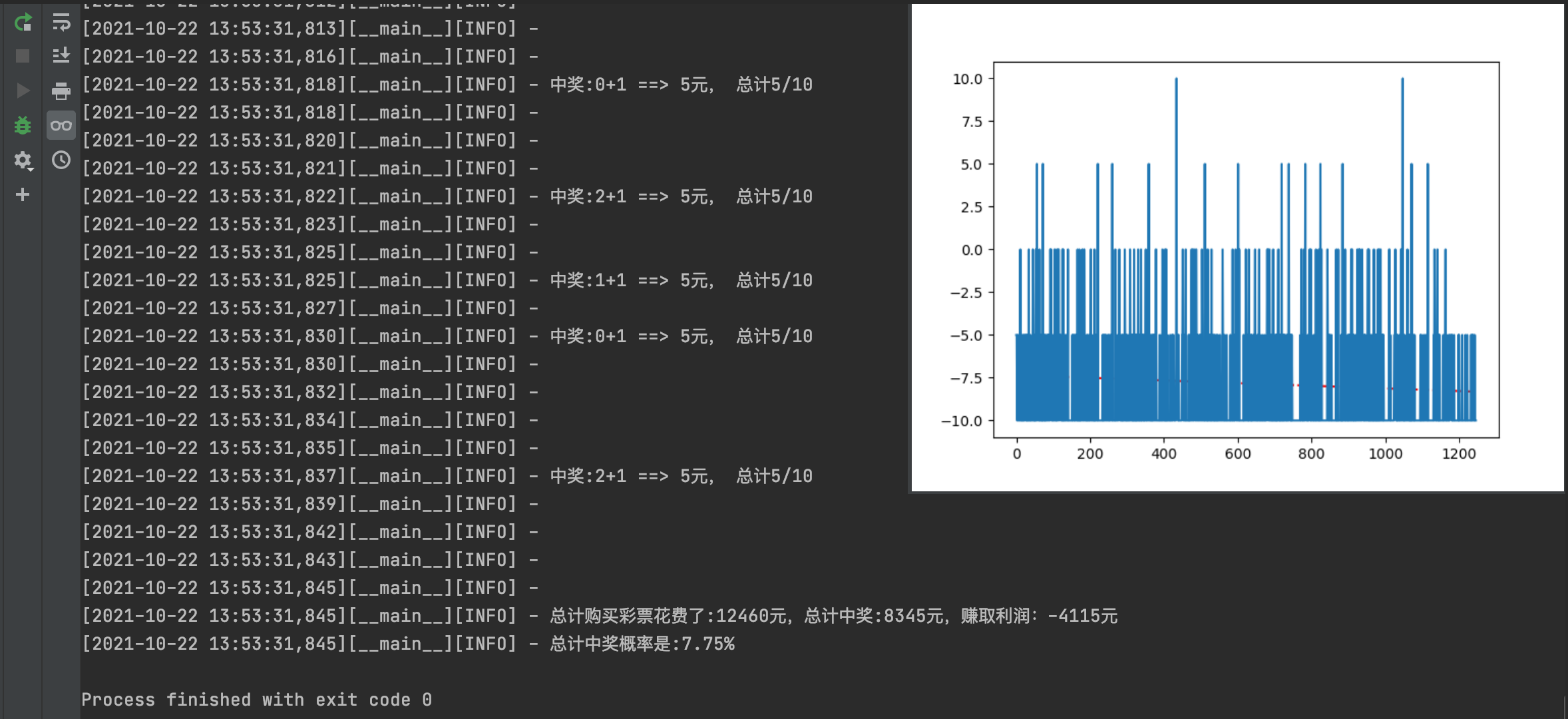
@hydra.main(config_path="../config", config_name="config") def do_predict(cfg): _logger.info('使用如下配置开始预测:\n' + omegaconf.OmegaConf.to_yaml(cfg)) # 第 1 步: 初始化机选种子数,以及缓存路径。 train.set_random_seed(cfg['training']['random_seed']) _logger.info('Step 1: 预测--初始化种子数据。') # STEP 2: 通过配置文件,加载数据集,以及训练过程函数。 # 预先处理数据集中的特征:和值=平均数,跨度,奇偶,重复上期数,三区比, train_dataset = dataset.LotteryDataSet.from_config(cfg['dataset']) if train_dataset is None or len(train_dataset.origin_data) <= 0: raise Exception("数据集缺失,并未找到合适的数据集") _logger.info('Step 2: 预测--加载数据集,最后一期是:' + str(train_dataset.origin_data[-1])) data_transform = transform.LotteryDataTransform() train_dataset = data_transform(train_dataset) _logger.info(' 预测--数据集数字化变换...' + str(train_dataset)) # STEP 3: 通过配置文件的配置,创建训练模型 mdl_cfg = cfg.get('model', {}) dt_cfg = cfg.get('dataset', {}) opt_cfg = cfg.get('optimizer', {}) train_cfg = cfg.get('training', {}) # 调用一次模型,初始化所有权重信息 model = train.build_model( model_config={**mdl_cfg, **dt_cfg, **opt_cfg}, ) # 读取正式模型参数 mdl_path = mdl_cfg.get("model_save_path", None) mdl_path = common_utils.get_model_final_save_path(cfg, mdl_cfg.get('name', ''), mdl_path) train.load_model_weights(model, mdl_path, True) # STEP 4: 使用数据集中的预测数据,对下一期号码进行预测 predict_cfg = cfg.get('predict', {}) train.set_random_seed(None) # 是否要进行模拟购买 if predict_cfg.get('simulates', False): _logger.info('预测-即将开始模拟购买测试:') total_benifits = [] total_cost = 0 total_win = 0 total_buy = 0 total_hit = 0 predict_ret = model.predict(train_dataset.test_np_x, batch_size=train_cfg['batch_size']) for i in range(len(predict_ret[0])): cost = 0 win = 0 one_ret = [] for x in predict_ret: dim_length = len(x[i]) one_ret.append(x[i].reshape(-1, dim_length)) real_ball = gen_ball_str(train_dataset.test_np_y, i, front_size=dt_cfg['front_size'], back_size=dt_cfg['back_size']) cost += 10 total_cost += cost total_buy += 5 for buy in range(5): balls = common_utils.get_ball_from_predict_result(one_ret, front_wants=dt_cfg['front_size'], back_wants=dt_cfg['back_size']) f, b = common_utils.calculate_hits(real_ball, balls) award = train_dataset.cal_award(f, b) win += award total_win += win if award > 0: _logger.info(f"中奖:{f}+{b} ==> {award}元, 总计{win}/{cost}") total_hit += 1 total_benifits.append(win - cost) _logger.info('') _logger.info(f"总计购买彩票花费了:{total_cost}元,总计中奖:{total_win}元,赚取利润:{total_win - total_cost}元") _logger.info(f"总计中奖概率是:{round(total_hit/total_buy,4)*100}%") common_utils.draw_graph(total_benifits) else: _logger.info('预测-即将开始预测:') predict_ret = model.predict(train_dataset.predict_np_x, batch_size=train_cfg['batch_size']) balls = common_utils.get_ball_from_predict_result(predict_ret, **{**predict_cfg, **dt_cfg}) _logger.info("预测完毕,结果是:{}".format(balls))这里注意,有一个分支是专门用来评估预测效果的。
按照列好的提纲,这个应该下一步骤再讲的。没关系,我们下一个节点来评估整体程序的预测效果。
评估预测效果
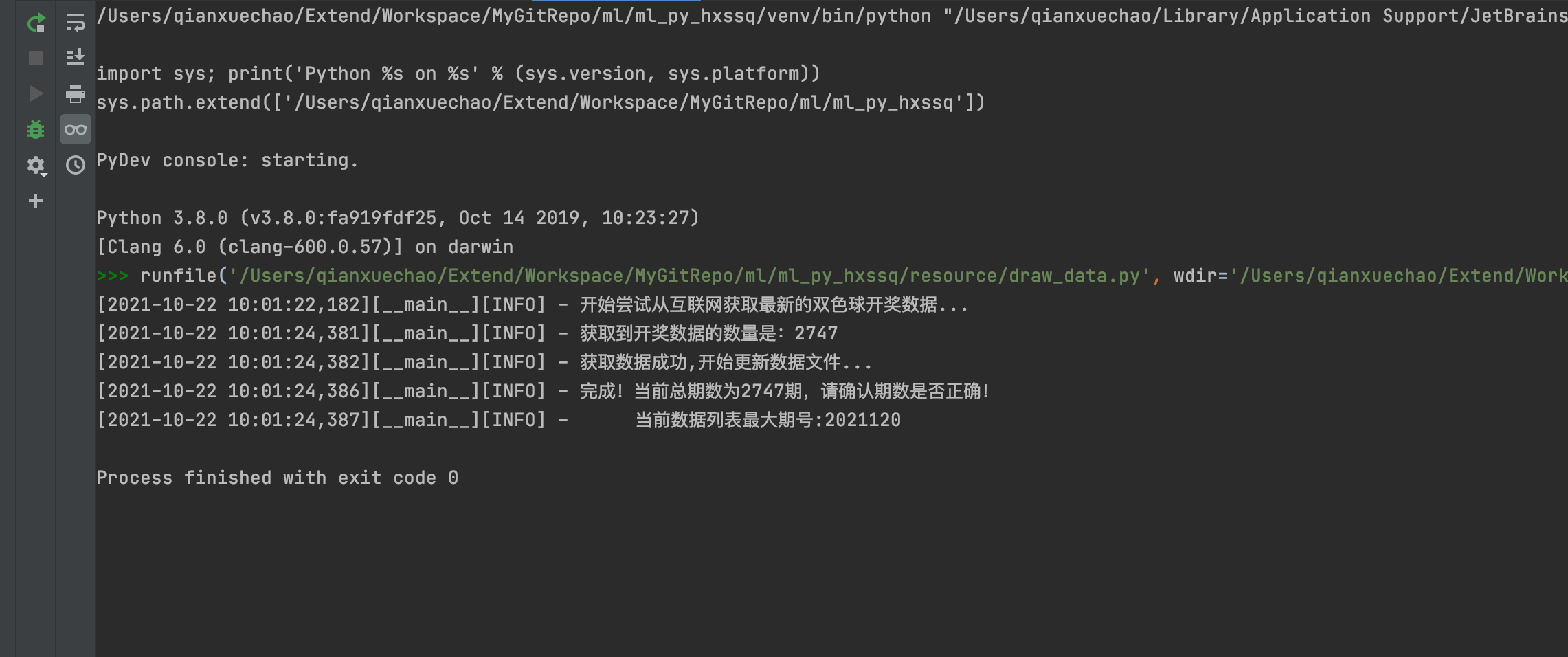
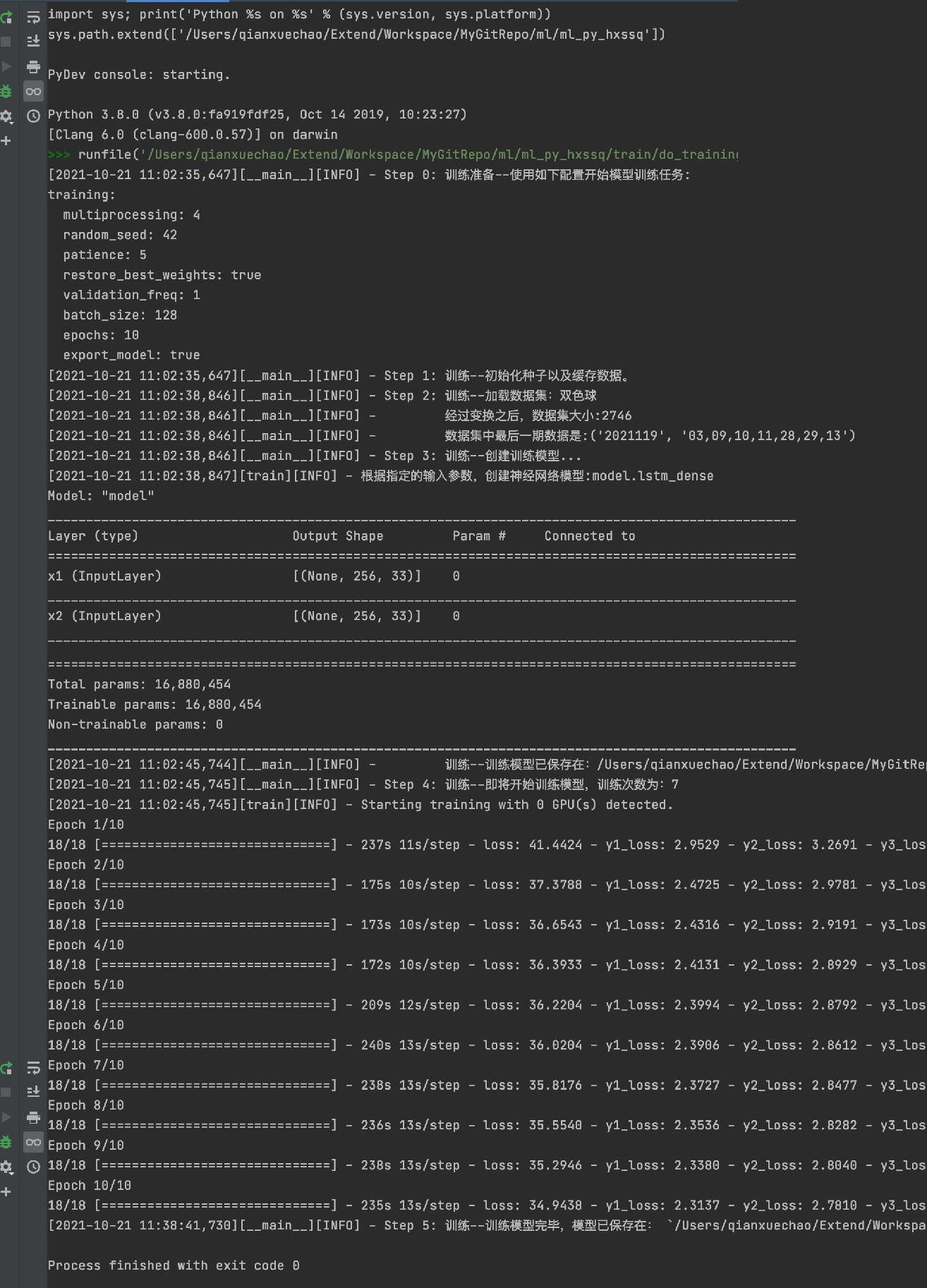
数据抓取:
模型训练:
数据预测:
效果评估:
由此可见,机器学习的预测效果还是不错的。虽然不能保障盈利,赚钱,但是可以让你减少一点损失。
你可能要说了,你咋知道可以减少损失呢?
来看这张图,可以看到,随机去购买彩票的中奖概率,是:
【6.74%】
而通过机器学习,获取到的中奖概率是:
【7.75%】
提高了一个百分点还要多一些。
当然,实际上,几乎无感,你买100次,多中一次奖而已。



评论区